안녕하세요, 한국방송통신대학교 교육학과 3학년 알음입니다.
본 글은 한국방송통신대학교 2024년 봄학기 '데이터시각화' 기말 과제 제출물을 원문 그대로 가져온 글입니다.
이제 통계/데이터 과학 전공 공부의 첫 걸음을 내딛은 단계인 제가 쓴 글이기 때문에 미숙한 부분이 많으니 향후 동일한 과제를 준비하시는 과정에서 본 글을 찾으신 학우님들께서는 참고만 해주시길 부탁드리며, 본 글과 관련된 의견 또는 질문은 댓글로 달아주시면 감사하겠습니다.

Q1. 뉴스(인터넷, TV, 신문 등)에 데이터 시각화가 쓰인 사례를 찾아서 다음을 작성하시오.
1.
뉴스의 제목, 날짜, 게재된 매체 이름
2.
데이터 시각화 (사진이나 캡쳐 이미지를 붙일 것)
3.
데이터 시각화를 통해 어떤 내용을 전달하였는지
4.
데이터 시각화가 얼마나 효율적, 효과적으로 이루어졌는지 본인의 평가
① 뉴스의 제목, 날짜, 게재된 매체 이름
•
② 데이터 시각화 (사진이나 캡쳐 이미지를 붙일 것)

③ 데이터 시각화를 통해 어떤 내용을 전달하였는지
•
‘대한민국 치매 실종 종합 보고서’를 표방한 기획 콘텐츠 시리즈
•
치매 환자의 시야에서 바라본 산책길을 간접 체험할 수 있는 콘텐츠
•
‘행복 GPS’ 배회감지기 이용자(=치매 환자)의 6개월치 GPS 동선 분석 결과
④ 데이터 시각화가 얼마나 효율적, 효과적으로 이루어졌는지 본인의 평가
급격한 고령화를 겪고 있는 우리나라에서 치매 노인 돌봄 체계 부족은 중요도와 시급성이 빠르게 올라가고 있는 사회적 문제임에도 불구하고 관련 연구와 자료는 턱없이 부족한 상태입니다. 저 또한 외조부와 외조모 두 분께서 치매 합병증으로 인해 돌아가셨음에도 치매에 대한 이해도는 아직 많이 낮은 상태입니다.
치매는 특성 상 현재 환자가 경험하고 있는 어려움을 주위에서 이해하기가 무척 어렵습니다. 의사소통 능력이 사실상 상실된 상태이기 때문에 신체적 변화에 대해 표현이 불가능하기 때문입니다. 그렇기 때문에 치매로 인해 배회하는 환자를 매번 찾아야 하는 가족은 불편감을 넘어 지속적인 정신적 피로 누적에 시달리게 됩니다.
본 프로젝트는 약 1개월에 걸쳐 여러 차례의 보도를 통해 국내 치매환자 실종 케이스 증가 추이 자료와 관련 정책적 제언을 대중에게 제시했다는 점도 좋았지만, 세계 최초로 치매 환자의 배회 패턴을 GPS를 통해 분석하고 그 결과를 시각화해서 인터렉티브 콘텐츠 형태로 제시했다는 점에서 큰 의미가 있습니다. 앞서 서술한 것 같이 대중이 직접 체험하기 어려운 ‘치매 환자의 시야’를 경험할 수 있는 콘텐츠를 구축하여 각종 텍스트 기반 데이터보다 직관적으로 치매 환자를 이해할 수 있도록 했다는 점에서 대중의 공감과 변화를 효과적이고 효율적으로 이끌어 냈습니다.
실제로 한국일보 엑설런스랩은 본 기획과 후속 프로젝트인 치매 환자 인식 개선 켐페인 ‘기억해 챌린지’를 통해 치매 문제에 대한 대중의 관심을 환기했고, 그 결과 보건복지부(치매 실종 예방 정책 개선 방안 약속), 한국취약노인지원 재단 및 독거 노인 종합 센터(치매 어르신 영양 도시락 사업) 등의 정책적 변화를 이끌어냈습니다. 이는 그간의 다양한 치매 관련 연구 사례에 비해 더 큰 파급효과를 만든 결과이며, 이 과정에서 인터렉티브 기반 데이터 시각화 콘텐츠가 큰 역할을 했습니다.
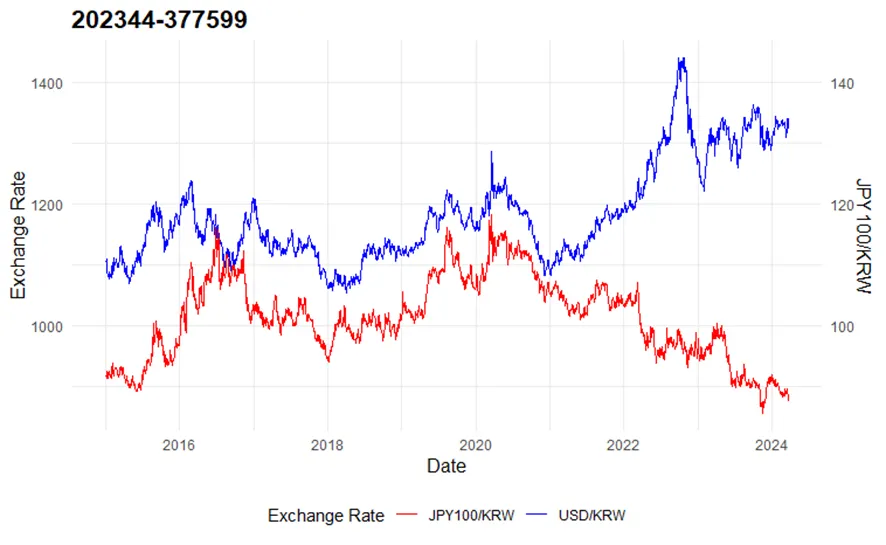
Q2. 2015년 1월 2일부터 2024년 3월 21일까지 원/달러 환율과 원/100엔 환율의 변화를 선그래프로 시각화하시오. 하나의 화면에 2개의 꺾은 선을 겹쳐서 그리시오.
•
데이터는 박서영 교수 홈페이지 자료실에서 ‘currency_data.xlsx’ 파일을 받아서 사용하시오.
•
변수 USD_to_KRW는 원/달러 환율을, 변수 JPY100_to_KRW는 원/100엔 환율을 나타내며, 변수 date는 날짜를 나타낸다.
•
그래프의 제목으로 본인의 학번을 출력하시오.
•
실행 코드
# 필요한 패키지 로드
library(readxl)
library(ggplot2)
library(dplyr)
# 엑셀 파일 읽어오기 : 해당 경로 내에 xlsx 파일 사전 저장 필요
data <- read_excel("C:/Users/Admin/Downloads/currency_data.xlsx")
# 데이터 전처리
data <- data %>%
mutate(date = as.Date(date))
# 선그래프 그리기
ggplot(data, aes(x = date)) +
geom_line(aes(y = USD_to_KRW, color = "USD/KRW")) +
geom_line(aes(y = JPY100_to_KRW, color = "JPY100/KRW")) +
labs(title = "202344-377599",
x = "Date",
y = "Exchange Rate",
color = "Exchange Rate") +
scale_color_manual(values = c("USD/KRW" = "blue", "JPY100/KRW" = "red")) +
scale_y_continuous(sec.axis = sec_axis(~./10, name = "JPY100/KRW")) +
theme_minimal() +
theme(
plot.title = element_text(size = 16, face = "bold"),
axis.title = element_text(size = 12),
legend.position = "bottom"
)
R
복사
•
실행 결과
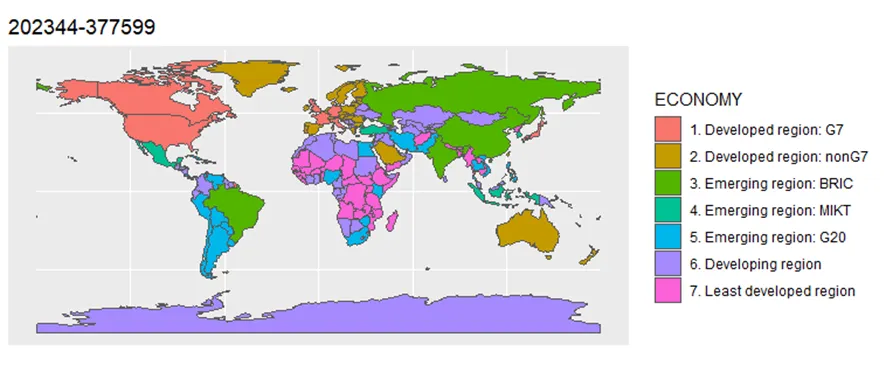
Q3. 교재 7장 4절 <벡터 데이터의 시각화>와 해당 부분 동영상 강의에서 사용한 Natural Earth 데이터(ne_110m_admin_0_countries.shp와 동반 파일)를 사용하여 세계 지도를 그리시오.
•
Natural Earth 데이터에 있는 ECONOMY 변수는 각 국가를 경제 수준에 따라 일곱 개의 그룹으로 구분한 변수이다. 이 변수를 이용하여, 각 국가의 경제 수준 그룹을 세계 지도 위에 영토의 색으로 나타내시오.
•
그래프의 제목으로 본인의 학번을 출력하시오.
•
실행 코드
# 필요한 패키지 로드
install.packages("sf")
library(ggplot2)
library(sf)
# 벡터 데이터 읽어오기
setwd("C:/Users/Admin/Downloads/Datasets_for_ch7")
NE.countries <- read_sf("ne_110m_admin_0_countries.shp")
NE.countries
st_crs(NE.countries)
# 벡터 데이터 시각화
ggplot() + geom_sf(data=NE.countries)
# ECONOMY 변수의 도수분포표
table(NE.countries$ECONOMY)
# 각 국가의 ECONOMY 변수를 지도상에 영토의 색으로 출력
ggplot() +
geom_sf(data=NE.countries, aes(fill=ECONOMY)) +
labs(title = "202344-377599", subtitle = NULL)
R
복사
•
실행 결과

본 글은 독자 여러분의 이해와 준비를 돕기 위한 글로, 본 글의 작성자는 본 글의 내용상 오류나 누락에 대해 어떠한 책임이나 의무도 부담하지 않습니다.
본 블로그의 모든 글에 대한 저작권은 저에게 귀속되나, 내용의 수정 없이 출처를 밝히고 공유하는 것은 가능합니다. 글을 공유하실 때에는 공유해가신 곳을 각 글의 리플로 남겨주시면 감사하겠습니다.
Last updated 2024.05.04
Copyright ⓒ2024, 알음(이은지) All Rights Reserved.
