안녕하세요, 한국방송통신대학교 교육학과 3학년 알음입니다.
본 글은 한국방송통신대학교 2024년 봄학기 '데이터시각화' 출석수업 대체 과제 제출물을 원문 그대로 가져온 글입니다.
이제 통계/데이터 과학 전공 공부의 첫 걸음을 내딛은 단계인 제가 쓴 글이기 때문에 미숙한 부분이 많으니 향후 동일한 과제를 준비하시는 과정에서 본 글을 찾으신 학우님들께서는 참고만 해주시길 부탁드리며, 본 글과 관련된 의견 또는 질문은 댓글로 달아주시면 감사하겠습니다.

Q1. 좋은 데이터 시각화의 사례를 1개 찾고 어떤 점에서 훌륭한지 300자 이내로 서술하시오.
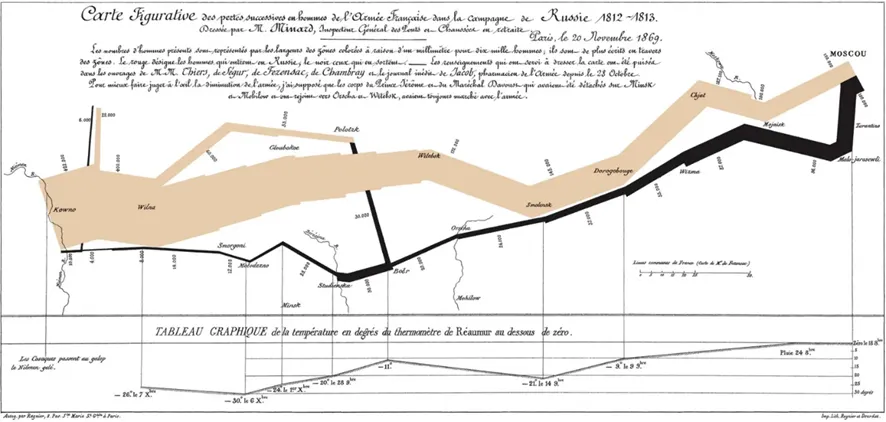
첫 번째로, 본 차트는 다양한 정보를 통합하여 제공하고 있습니다. 온도 그래프와 지도, 설명 텍스트가 결합되어 있기 때문에 한 눈에 많은 정보를 파악할 수 있도록 돕습니다. 특히, 차트 하단의 온도 그래프는 원정에 중요한 영향을 미친 환경 요인으로서의 기온의 변화 양상을 시각적으로 제시합니다.
두 번째로, 공간 정보를 포함한 다양한 변수의 시각화 방법에 대한 힌트를 제공합니다. 원정군 규모의 변화를 선의 두께로, 이동 방향을 선의 색으로 표현하여 원정 경로를 지도 위에 표현하여 원정 경로를 독자가 쉽게 이해할 수 있게 합니다.
Q2. 한스 로슬링의 TED 강의를 보고 데이터 시각화의 역할 등 느낀 점을 1페이지 이내로 정리하시오.
‘팩트풀니스’ 공저자 중 한 분인 한스 로슬링 교수님은 UN 데이터 기반 연구논문 및 통계 정보 제공 도구인 ‘갭마인더’를 만드신 분입니다. 갭마인더의 여러 자료는 우리로 하여금 ‘지금 상식이라고 생각하는 것이 사실이 맞습니까?’라는 의심을 가질 수 있게 돕고 있습니다. 즉, ‘팩트풀니스’의 한국어판 표지에 기재된 ‘우리가 세상을 오해하는 10가지 이유와 세상이 생각보다 괜찮은 이유’를 우리에게 알려주며, 이를 통해 실제 데이터에 기반의 현실 인식을 통해 편견을 극복할 수 있도록 돕습니다.
이러한 사고의 전환 과정에 필요한 시간을 단축하고, 더 많은 사람에게 데이터의 올바른 해석이 전달될 수 있도록 돕는 것이 데이터 시각화의 강력한 기능입니다. 데이터 시각화는 통계학자인 한스 로슬링 교수님이 더 많은 대중을 대상으로 짧은 시간 내에 UN 제공 데이터 내에 숨어 있는 사실과 맥락을 전달할 수 있도록 하며, ‘팩트풀니스’를 읽을 여건이 되지 않는 사람도 훨씬 짧은 시간 사이에 동일한 문제 의식을 공유할 수 있도록 다양한 데이터를 압축적으로 전달합니다.
어떤 데이터 분석 절차가 ‘분석’ 그 자체만으로 필요를 충족하고 업무가 종료될 수 있다면 데이터 시각화를 생략하겠으나, 현실적으로 그런 상황은 거의 없습니다. 대부분의 데이터 시각화는 후속 의사결정 및 행동 변화를 위한 이해관계자 대상의 커뮤니케이션을 수반하고, 해당 커뮤니케이션 단계에서 가장 강력한 설득 수단 중 하나가 데이터 시각화입니다. 인간은 정보 수용 과정에서 여러 감각 중 시각에 대한 의존도가 가장 높으며, 특히 복잡한 정보의 처리에 있어 시각은 다른 감각에 비해 빠르고 정확한 정보 전달 및 처리가 가능하기 때문입니다.
저는 올해 신설된 국가기술자격시험인 경영정보시각화능력 자격증 취득을 준비 중에 있습니다. 이번 학기 데이터 시각화 수업에서 학습한 내용을 기반으로 해당 자격증을 취득한 후 데이터 시각화 역량 향상을 위해 꾸준히 노력하겠습니다.
Q3. R의 datarium 패키지에 내장된 marketing 데이터셋은 광고 미디어에 사용한 비용과 판매액의 데이터이다. 변수 facebook은 facebook 광고비로 사용한 금액이고, 변수 sales는 판매액이다.
1.
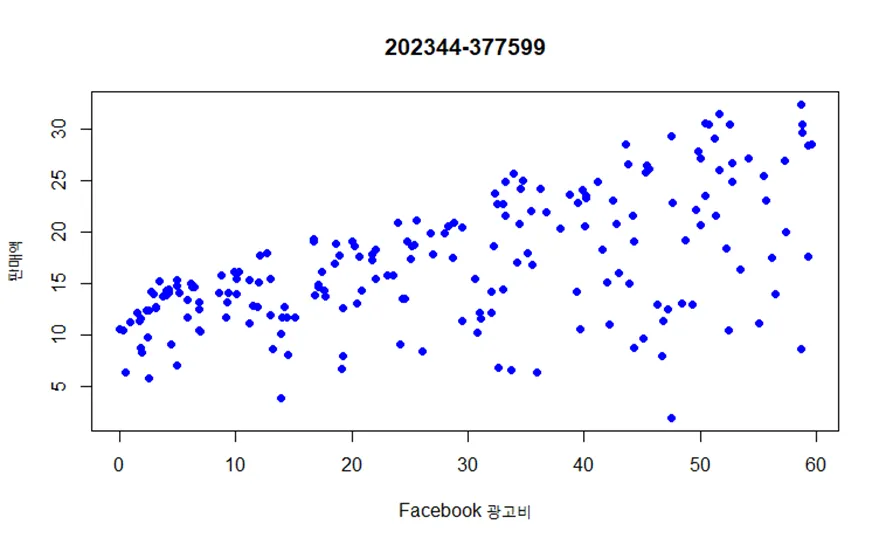
facebook 광고비(facebook)를 가로축, 판매액(sales)를 세로축으로 하는 산점도를 그리시오.
2.
facebook을 독립변수(설명변수)로, sales를 종속변수(반응변수, 결과변수)로 하는 회귀직선을 산점도 위에 그리시오. 산점도의 제목으로 본인의 학번을 출력하시오.
(1) facebook 광고비(facebook)를 가로축, 판매액(sales)를 세로축으로 하는 산점도를 그리시오.
•
실행 코드
# datarium 패키지 설치 및 로드
install.packages("datarium")
library(datarium)
# marketing 데이터셋 로드
data(marketing)
# 산점도 그리기
plot(marketing$facebook, marketing$sales,
xlab = "Facebook 광고비",
ylab = "판매액",,
pch = 16, col = "blue")
# 산점도 제목 설정
title(main = "202344-377599")
R
복사
•
실행 결과
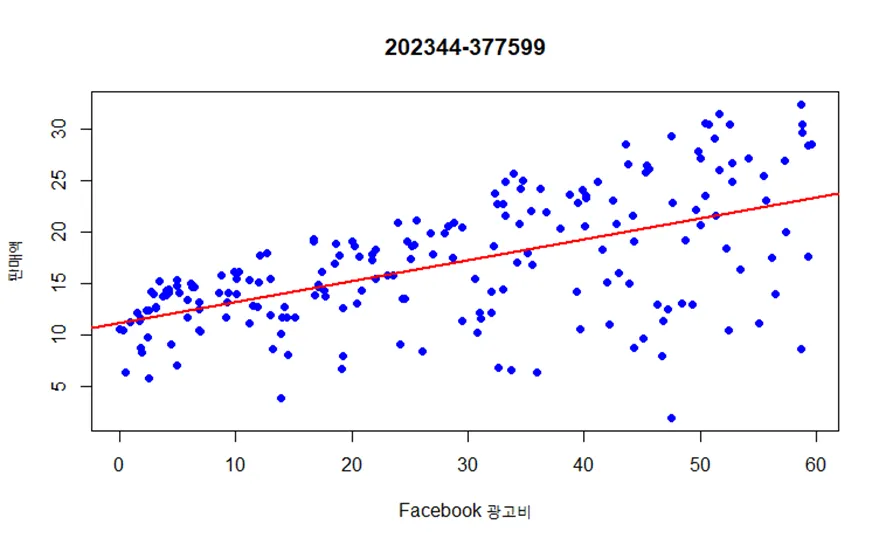
(2) facebook을 독립변수(설명변수)로, sales를 종속변수(반응변수, 결과변수)로 하는 회귀직선을 산점도 위에 그리시오. 산점도의 제목으로 본인의 학번을 출력하시오.
•
실행 코드
# 필요한 패키지 로드
install.packages("datarium")
library(datarium)
data(marketing)
plot(marketing$facebook, marketing$sales,
xlab = "Facebook 광고비", ylab = "판매액",
pch = 16, col = "blue")
# 회귀모형 적합
model <- lm(sales ~ facebook, data = marketing)
# 회귀직선 그리기
abline(model, col = "red", lwd = 2)
# 산점도 제목 설정
title(main = "202344-377599")
R
복사
•
실행 결과
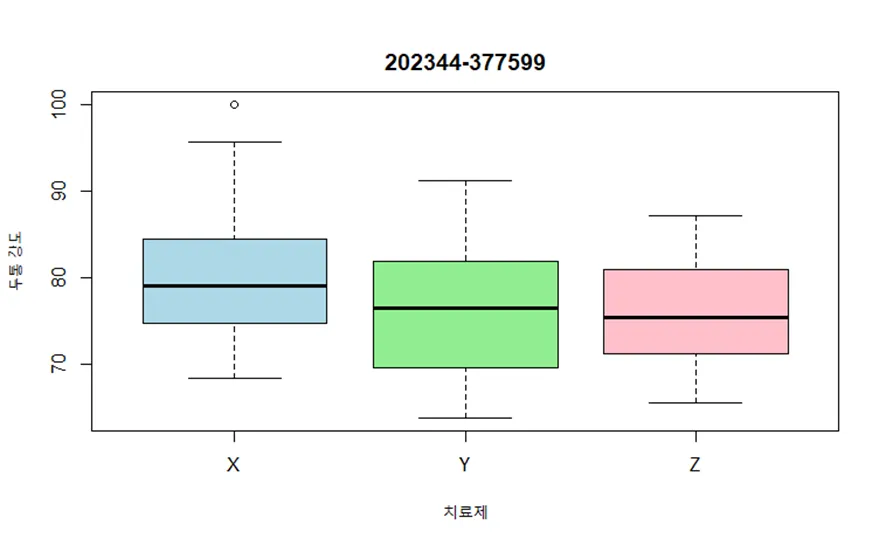
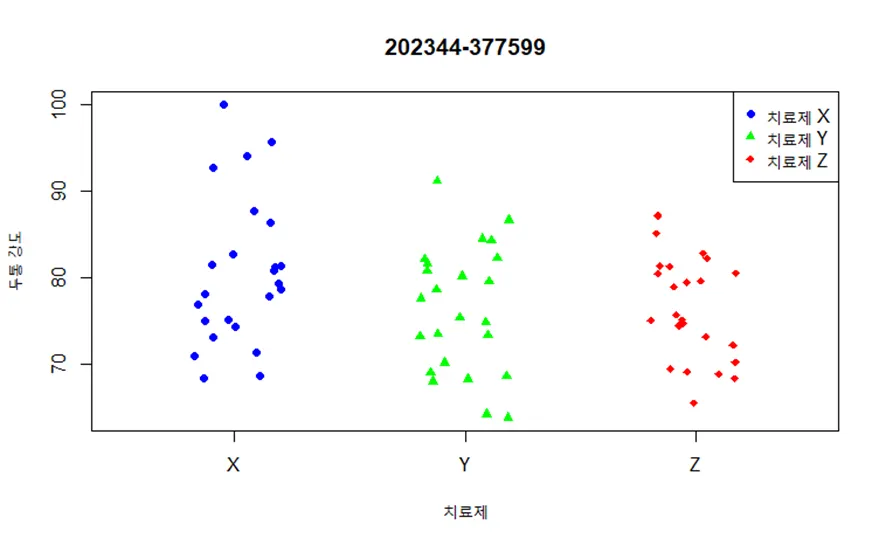
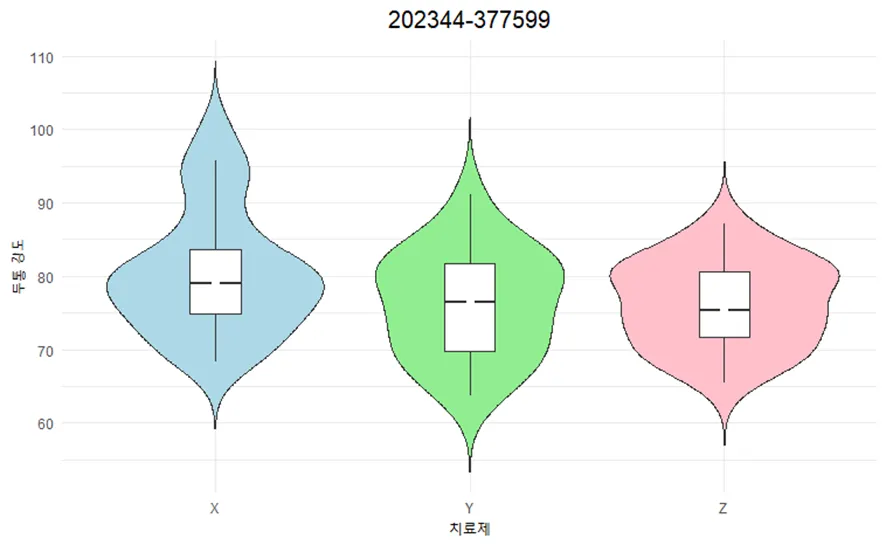
Q4. R의 datarium 패키지에 내장된 headache 데이터셋은 두통 치료제에 대한 임상시험에 참가한 두통 환자 72명의 데이터이다. 변수 treatment는 세가지 치료제 X, Y, Z 중 어느 치료제를 받았는지 나타내며, 변수 pain_score는 치료제를 투약한 후 두통의 강도를 점수로 나타낸 것이다. 이 데이터에서 치료제에 따라 두통의 강도의 분포가 어떻게 다른지 드러내는 데이터 시각화를 수행하시오. 그래프의 제목으로 본인의 학번을 출력하시오.
•
실행 코드
# 필요한 패키지 로드
install.packages("datarium")
library(datarium)
library(ggplot2)
data(headache)
# 1번(박스플롯) : 박스플롯 그리기
boxplot(pain_score ~ treatment, data = headache,
xlab = "치료제", ylab = "두통 강도",
col = c("lightblue", "lightgreen", "pink"),
border = "black")
# 학번을 그래프 제목으로 출력
title(main = "202344-377599", line = 1)
# 2번(산점도) : 치료제 별로 다른 마커 모양 지정
# jitter() 함수 : 가로축의 값을 약간 무작위로 변환 → 겹치는 점들을 구분할 수 있도록 함.
plot(pain_score ~ jitter(as.numeric(treatment)), data = headache,
xlab = "치료제", ylab = "두통 강도",
main = "202344-377599",
pch = c(16, 17, 18)[as.numeric(headache$treatment)],
col = c("blue", "green", "red")[as.numeric(headache$treatment)],
xlim = c(0.5, 3.5), xaxt = "n")
# 가로축 눈금 및 레이블 설정
axis(1, at = 1:3, labels = c("X", "Y", "Z"))
# 범례 추가
legend("topright", legend = c("치료제 X", "치료제 Y", "치료제 Z"),
pch = c(16, 17, 18), col = c("blue", "green", "red"))
# 3번(바이올린 플롯) : 바이올린 플롯 그리기
ggplot(headache, aes(x = treatment, y = pain_score, fill = treatment)) +
geom_violin(trim = FALSE) +
geom_boxplot(width = 0.2, fill = "white", outlier.shape = NA) +
stat_summary(fun = median, geom = "point", size = 2, color = "white") +
xlab("치료제") +
ylab("두통 강도") +
ggtitle("치료제에 따른 두통 강도 분포") +
scale_fill_manual(values = c("lightblue", "lightgreen", "pink")) +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 15),
legend.position = "none") +
labs(title = "202344-377599", subtitle = NULL)
R
복사
•
박스플롯 실행 결과
•
산점도 실행 결과
•
바이올린 플롯 실행 결과

본 글은 독자 여러분의 이해와 준비를 돕기 위한 글로, 본 글의 작성자는 본 글의 내용상 오류나 누락에 대해 어떠한 책임이나 의무도 부담하지 않습니다.
본 블로그의 모든 글에 대한 저작권은 저에게 귀속되나, 내용의 수정 없이 출처를 밝히고 공유하는 것은 가능합니다. 글을 공유하실 때에는 공유해가신 곳을 각 글의 리플로 남겨주시면 감사하겠습니다.
Last updated 2024.05.04
Copyright ⓒ2024, 알음(이은지) All Rights Reserved.
